



Категория: Инструкции
Презентацию к лекции Вы можете скачать здесь .
Начиная с середины XX века, программирование проделало большой путь и постоянно продолжает развиваться. Вспомним не такие уж далекие времена, когда наши коллеги писали свои программы в машинных кодах, непосредственно работая со справочником, содержащим информацию о поддерживаемом в процессоре наборе команд. Сейчас уже трудно представить, что в стиле "3E; 24; 5F…" можно написать сколько-нибудь серьезную программу, а ведь когда-то это было реальностью. В 1992 году в 10 классе школы одноклассник автора данной лекции самостоятельно, без чьей-либо помощи, кроме, быть может, моральной, написал в машинных кодах среду программирования с текстовым редактором и транслятором языка BASIC для ПК "Корвет". В то же время Ваш покорный слуга и его друзья-школьники по обрывочным, перепечатанным много раз брошюрам осваивали и применяли на практике язык Ассемблер для ПК "ZX SPECTRUM ", построенного на базе восьмиразрядного процессора Z80. Да, в то время тоже можно было писать на BASIC и других высокоуровневых языках, но в этом случае быстродействие программ оставляло желать лучшего, а доступ к ряду возможностей процессора был закрыт вовсе. В наши времена программирование в машинных кодах практически стало историей, а разработка программ на ассемблере имеет смысл в весьма ограниченном числе случаев. Одна из причин этого – невероятно возросший интеллект компиляторов языков высокого уровня C, C++, Fortran, ориентированных на высокопроизводительные вычисления (high performance computing. HPC ). Ни на миг не отвлекаясь от главной задачи – генерации корректного кода, оптимизирующие компиляторы умудряются выполнять многочисленные эквивалентные (точно или с точностью до разрешенных отклонений, например, при изменении порядка операций с плавающей запятой) преобразования, изменяя наш код до неузнаваемости и обеспечивая производительность. часто сопоставимую с хорошей программой на ассемблере. Отметим, что оптимизирующие компиляторы (в частности, одни из лучших представителей данной группы – Intel C/C++ Comiler, Intel Fortran Compiler ) умеют использовать новые наборы команд и генерировать код, ориентированный на современные центральные процессоры.
Остановимся на данном аспекте подробнее. Что значит "код, ориентированный на современные центральные процессоры"? Важный момент состоит в использовании новых команд и наборов команд, добавленных в процессор его производителем. Чтобы понять, почему это важно, обсудим возможные перспективы расширения функциональности процессора в результате добавления новых команд. Первая мысль, которая приходит в голову, звучит так: почему бы инженерам не поместить в набор команд часто используемые в научных и инженерных приложениях, составляющих основу области HPC. вычисление математических функций (sin, cos. exp. pow, …), генератор случайных чисел и многие другие полезные возможности? К сожалению, аппаратная реализация подобных "команд" весьма сложна и требует добавления значительного числа дополнительных транзисторов, что приведет к неприемлемому увеличению размера, энергопотребления и стоимости процессора. Таким образом, любое расширение набора команд является важным событием, не остается незамеченным в индустрии и быстро "подхватывается" разработчиками компиляторов. Действительно, раз уж несмотря на все трудности создатели процессора смогли добавить дополнительные команды, имеет смысл предоставить доступ к ним широкому кругу разработчиков ПО. использующих языки программирования высокого уровня.
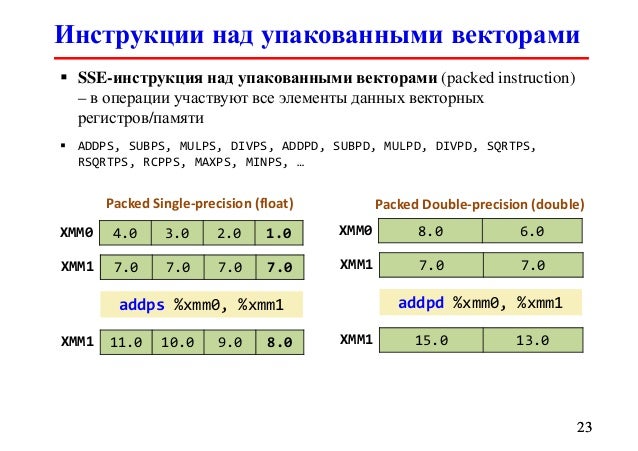
Данная лекция рассматривает одно из важных направлений развития наборов команд в рамках современных архитектур – векторные расширения. Что такое векторные расширения? Это дополнение в набор команд процессора, содержащее специализированные типы данных, регистры и инструкции, ориентированные на использование парадигмы SIMD – Single Instruction Multiple Data. Суть парадигмы SIMD заключается в выполнении одной командой однотипных операций над пакетом данных. При этом реализуется один из видов параллельной обработки данных, что открывает возможность существенного повышения производительности вычислительных программ. Разумеется, не во всех практических приложениях векторизация – использование векторных инструкций – позволяет добиться существенного прироста производительности. Казалось бы – все просто. Пусть мы обрабатываем числа двойной точности, имеем специальные регистры, позволяющие хранить по 4 таких числа, а также арифметические команды. позволяющие векторно выполнять операции ( рис. 4.1 ).
Рис. 4.1. Векторное сложение
На первый взгляд, мы можем ожидать ускорение вычислений до четырех раз по сравнению с обычным (скалярным) кодом. Однако на практике этого зачастую не происходит. Во-первых, присутствуют определенные накладные расходы на упаковку данных в регистры и распаковку результатов расчета. В наилучшем случае мы можем загрузить/выгрузить данные одной командой. Для этого необходимо, чтобы данные лежали в памяти последовательно или (для некоторых векторных расширений) с определенным шагом. В последнем случае надо учитывать и эффективность использования особенностей иерархической организации подсистемы памяти. Во-вторых, может так случиться, что есть зависимость между значениями элементов векторов и некоторых результатов расчета – зависимости по данным, что делает невозможным параллельное выполнение операций. В связи с этим в некоторых случаях мы можем наблюдать, что несмотря на наши усилия компилятор отказывается генерировать векторный код, а иногда нам удается его уговорить, но мы не получаем осязаемого выигрыша во времени.
Тем не менее, спектр алгоритмов, для которых векторизация соответствующего программного кода является одним из важных ресурсов повышения производительности, является достаточно большим. Так, для мультимедийных приложений характерно применение алгоритмов, многократно повторяющих однотипные операции над большими массивами данных. При выполнении инженерных расчетов во многих случаях удается успешно векторизовать хотя бы часть программы и получить выигрыш в производительности. Отметим также, что в современных центральных процессорах размер вектора в случае вычислений с одинарной точностью составляет 4 (наборы инструкций SSE ) и 8 (набор инструкций AVX), а для вычислений с двойной точностью – 2 (наборы инструкций SSE ) и 4 (набор инструкций AVX). Таким образом, избегая векторизации расчетных частей алгоритма, мы теряем до 87,5% производительности, что весьма существенно. В случае использования Xeon Phi мы можем констатировать еще больший вклад векторизации в общую производительность программы, поскольку размер вектора увеличился вдвое по сравнению с AVX. Таким образом, как на традиционных процессорах, так и, тем более, на ускорителях Xeon Phi умелое использование векторных расширений является одним из ключевых механизмов, влияющих на производительность программы.
Дальнейшее изложение материала о векторизации построено следующим образом. В данной лекции дается общее описание векторных расширений в Intel Xeon Phi и подходы к их использованию в программах на языках C/C++. В лекции №5 рассматриваются более "тонкие" особенности использования указанных расширений при написании прикладных программ на языках высокого уровня с использованием возможностей компиляторов Intel. Техника применения векторных вычислений формируется в " Оптимизация расчетов на примере задачи вычисления справедливой цены опциона Европейского типа " . на примерах иллюстрирующей некоторые типовые проблемы векторизации кода и методы их решения. В дальнейших практических работах векторизация неизменно упоминается и применяется в качестве одного из ключевых способов повышения производительности программ.
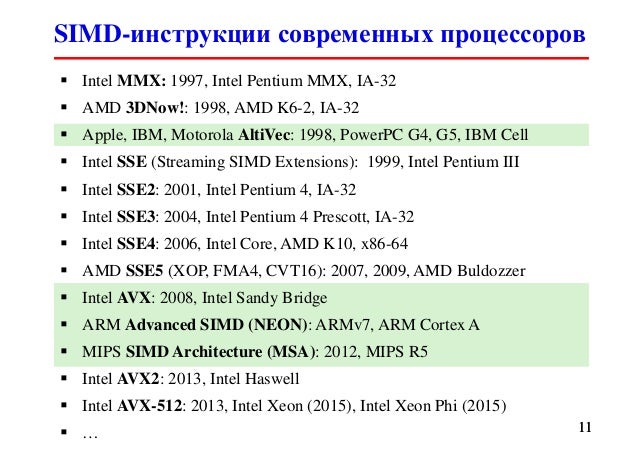
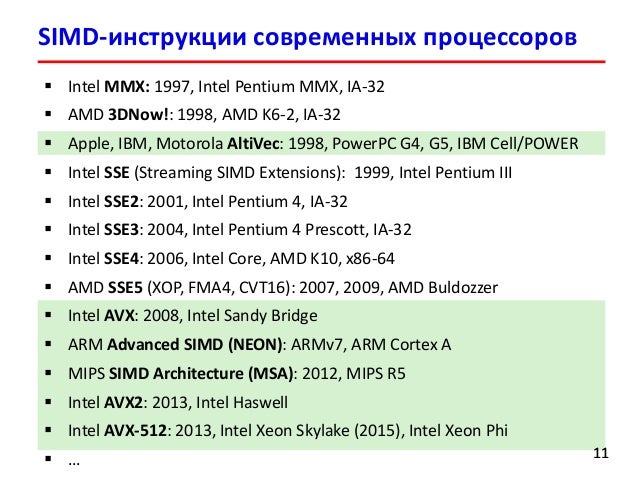
Векторные расширения. Краткий обзорВ настоящее время векторные расширения присутствуют в наборах команд процессоров различных производителей и архитектур. Так, в центральных процессорах Intel соответствующие наборы команд эволюционировали по пути MMX – SSE – SSE2 – SSE3 – SSE4 – AVX, преодолев путь от векторной целочисленной арифметики, организованной на специализированных 64-разрядных регистрах, и ориентированной преимущественно на обработку звука и видео, до широкого спектра арифметических операций с плавающей запятой, работающей на 256-разрядных регистрах, и операций управления работой подсистемы памяти. Рассматривая векторные расширения, необходимо упомянуть дополнение 3DNow. реализованное в процессорах AMD. а также расширение NEON. активно развивающееся в процессорах архитектуры ARM. широко распространенных во встраиваемых системах. Рассмотрим кратко векторные расширения, реализованные в Intel Xeon Phi. Данное описание не претендует на полноту. Оно призвано составить общее впечатление о сути вопроса для лучшего понимания того, как соотносится расчетный код на C/C++ и машинный/ассемблерный коды, порождаемые компилятором. Данное понимание весьма полезно при оптимизации программ по скорости их работы. Желающие познакомиться с вопросом в большем объеме могут обратиться к источникам [4.1] и [4.3] .
Типы данных и регистровый пулВ ядрах ускорителей Intel Xeon Phi сделан следующий шаг в развитии векторных расширений набора команд. Так, уже привычные для программистов MMX, SSE, AVX не поддерживаются. Однако вместо этого в каждом ядре сконструирован специальный модуль векторной обработки (VPU, vector processor unit), содержащий 32 512-разрядных регистра (zmm-регистры; отметим двукратное увеличение размера регистра по сравнению с AVX) и открывающий новые возможности по обработке данных с использованием векторных инструкций вида 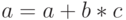 с однократным округлением (FMA, fused multiply–add), а также некоторых других возможностей.
с однократным округлением (FMA, fused multiply–add), а также некоторых других возможностей.
Итак, учитывая размер векторного регистра, на каждом ядре Intel Xeon Phi мы можем одновременно производить действия над 16 32-битными целыми числами или 8 64-битными целыми числами или 16 числами с плавающей запятой одинарной точности или 8 числами с плавающей запятой двойной точности. Кроме того, поддерживаются операции с комплексными данными. Заметим, что в отличие от привычных наборов команд в векторных расширениях Intel Xeon Phi большинство операций являются тернарными – имеют 2 аргумента и один результат, что по некоторым данным (см. например, [4.1] ), приводит к 20% росту производительности по сравнению с традиционной схемой работы, основанной на двух операндах. Для FMA все три операнда являются аргументами, при этом один из них в то же время принимает результат.
Обзор основных типов операцийПоддерживаются следующие основные операции:
Также реализованы следующие возможности:
В рамках Intel Xeon Phi была реализована расширенная поддержка некоторых математических функций. Так, появились команды для вычисления в одинарной точности функций 1/x, 1/sqrt(x), log2 (x), 2 x. Первые три инструкции имеют латентность 4 такта и пропускную способность 1 такт, последняя – латентность 8 тактов и пропускную способность 2 такта. Нетрудно видеть, что sqrt(x), a x и деление могут быть вычислены при помощи указанных функций. Вопрос о векторизации циклов, содержащих вызовы математических функций, будет рассмотрен позже.



Технология SMT – это, по сути, новое название технологии HT (Hyper-Threading), которая широко использовалась в процессорах Pentium 4 с микроархитектурой NetBurst. По непонятной причине при переходе к микроархитектуре Intel Core, она была сначала упразднена, но снова появилась в мобильных микропроцессорах Intel Atom и затем и в микропроцессорах архитектуры Nehalem, а теперь и в Sandy Bridge. Эта технология позволяет одному вычислительному ядру параллельно исполнять два потока команд за счет использования тех элементов ядра, которые простаивают при выполнении одного из потоков. При этом некоторые, особенно часто используемые элементы дублируются. Следовательно, с точки зрения операционной системы, четырехъядерный процессор Sandy Bridge, использующий эту технологию, будет рассматриваться как восьмиядерный. Конечно, в общем случае при этом производительность не будет удваиваться, поскольку эти восемь логических процессоров вынуждены делить между собой общий набор исполнительных модулей вычислительного ядра, однако суммарная производительность оказывается выше, по некоторым данным на 20 – 25%.
Сутью режима TurboMode (или TurboBoost ) является динамическая подстройка тактовых частот ядер процессора и их напряжения питания, в зависимости от уровня их загрузки и температуры процессора. Реализация этой функции возложена на специальный функциональный блок PCU(PowerControlUnit), который входит в «Systemagent » и отслеживает уровень загрузки ядер процессора, температуру процессора, а также отвечает за энергопитание каждого ядра и регулирование его тактовой частоты. Этот блок PCU состоит из более миллиона транзисторов и имеет даже свой микроконтроллер. Если какие-то ядра процессора оказываются незагруженными, они попросту отключаются от линии питания и их энергопотребление становится равным нулю. При этом, тактовая частота и напряжение питания остальных ядер динамически увеличивается, но таким образом, чтобы общее энергопотребление процессора не превышало его TDP(ThermalDesignerPower) – проектной мощности тепловыделения.
Более того, режим Turbo Mode в процессорах Intel Core i7реализуется и в том случае, когда изначально загружаются все ядра процессора, но при этом его энергопотребление не превышает значения TDP. При этом частота каждого ядра может динамически увеличиваться, но так, чтобы энергопотребление процессора не превышало этого, заданного в BIOS значения.
Технологииmacrofusion и micro-ops fusion
При декодировании инструкций в микроархитектуре Intel Core впервые были использованы технологии macrofusion и micro-opsfusion. которые используются и в микроархитектуре Sandy Bridge, с некоторыми усовершенствованиями.
Технология macrofusion призвана увеличить числа исполняемых за такт команд, и заключается в том, что ряд пар связанных между собой последовательностей Х86 инструкций, таких, например, как инструкция операции сравнения со следующей за ней инструкцией условного перехода, представляются одной микроинструкцией. Такая микроинструкция рассматривается планировщиком (scheduler) и выполняется на исполнительном устройстве как одна команда. Таким путем достигается как увеличение темпа исполнения кода, так и некоторая экономия энергии. Иллюстрация реализации технологии macrofusion на примере слияния инструкции сравнения и, следующей за ней, инструкции условного перехода приведена на рис.X.4. На нём показано, как за один такт декодируются и поступают из очереди команд в блоки декодирования одновременно пять инструкций Х86. В случае возможности слияния двух команд (macrofusion), появляется фактическая возможность параллельной обработки не 4, а 5 инструкций за такт (единовременно может образовываться не более одной макрокоманды, образованной способом слияния).
В микроархитектуре Sandy Bridge расширен набор команд, для которых возможно слияние макроопераций. Кроме того, в микроархитектуре Intel Core слияние макроопераций не поддерживалось для 64-битного режима работы процессора, то есть технология macrofusion была реализована только в 32-битном режиме. В процессорах микроархитектур Nehalem и Sandy Bridge это узкое место устранено, и операции слияния работают как в 32-, так и 64-битном режиме работы процессора.
Доброго времени суток всем форумчанам. Преподаватель подкинул задачку.
Вывести на дисплей одно из следующих сообщений: "Процессор не поддерживает команды SSE", "Процессор поддерживает команды SSE", "Процессор поддерживает команды SSE2", "Процессор поддерживает команды SSE3", "Процессор поддерживает команды SSE4", "Процессор поддерживает команды SSE5".
Не могли бы Вы помочь с написанием кода программы.
Я так понял, что нужно прочитать данные из регистра EDX. В связи с этим у меня возниает еще один вопрс:
Если с SSE и SSE2 понятно, что вроде это 25 и 26 биты регистра EDX (возможно ошибаюсь, если так, то обязательно меня поправьте, иначе пойду не в том направлении), то с SSE3, SSE4 и SSE5 вообще непонятно ничего.
Сообщ. #2. 29.04.12, 11:12
Описание команды CPUID читай.
Сообщ. #3. 29.04.12, 11:43

Насколько я видел, поддержка SSE3 и выше определяется перехватом исключения некоррекного опкода и попыткой выполнения соответствующей инструкции. Либо есть исключение, либо нет.
А вообще, вот:
Цитата 10.1 OVERVIEW OF SSE EXTENSIONS
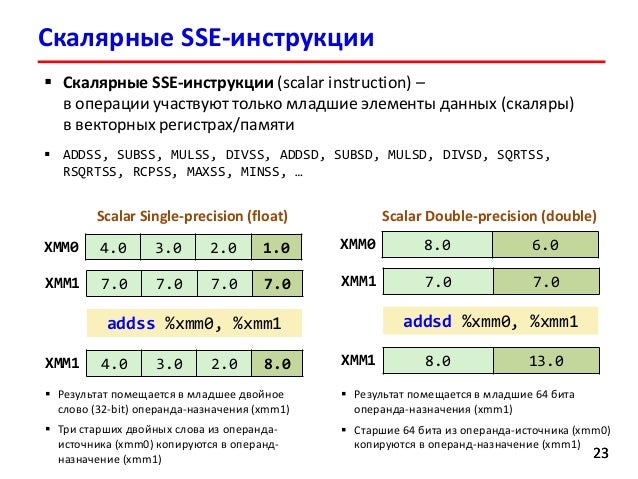
Intel MMX technology introduced single-instruction multiple-data (SIMD) capability into the IA-32 architecture, with the 64-bit MMX registers, 64-bit packed integer data types, and instructions that allowed SIMD operations to be performed on packed integers. SSE extensions expand the SIMD execution model by adding facilities for handling packed and scalar single-precision floating-point values contained in 128-bit registers.
If CPUID.01H:EDX.SSE[bit 25] = 1, SSE extensions are present.
.
Цитата 11.1 OVERVIEW OF SSE2 EXTENSIONS
SSE2 extensions use the single instruction multiple data (SIMD) execution model that is used with MMX technology and SSE extensions. They extend this model with support for packed double-precision floating-point values and for 128-bit packed integers.
If CPUID.01H:EDX.SSE2[bit 26] = 1, SSE2 extensions are present.
.
Цитата 12.4.2 Checking for SSE3 Support
Before an application attempts to use the SIMD subset of SSE3 extensions, the application should follow the steps illustrated in Section 11.6.2, “Checking for SSE/SSE2 Support.” Next, use the additional step provided below:Цитата 12.7.2 Checking for SSSE3 Support
Before an application attempts to use the SSSE3 extensions, the application should follow the steps illustrated in Section 11.6.2, “Checking for SSE/SSE2 Support.” Next, use the additional step provided below:Цитата 12.12.2 Checking for SSE4.1 Support
Before an application attempts to use SSE4.1 instructions, the application should follow the steps illustrated in Section 11.6.2, “Checking for SSE/SSE2 Support.” Next, use the additional step provided below:
Check that the processor supports SSE4.1 (if CPUID.01H:ECX.SSE4_1[bit 19] = 1), SSE3 (if CPUID.01H:ECX.SSE3[bit 0] = 1), and SSSE3 (if CPUID.01H:ECX.SSSE3[bit9] = 1).
Цитата 12.12.3 Checking for SSE4.2 Support
Before an application attempts to use the following SSE4.2 instructions: PCMPESTRI/PCMPESTRM/PCMPISTRI/PCMPISTRM, PCMPGTQ;the application should follow the steps illustrated in Section 11.6.2, “Checking for SSE/SSE2 Support.” Next, use the additional step provided below:
Check that the processor supports SSE4.2 (if CPUID.01H:ECX.SSE4_2[bit 20] = 1), SSE4.1 (if CPUID.01H:ECX.SSE4_1[bit 19] = 1), and SSSE3 (if CPUID.01H:ECX.SSSE3[bit 9] = 1).
Before an application attempts to use the CRC32 instruction, it must check that the processor supports SSE4.2 (if CPUID.01H:ECX.SSE4_2[bit 20] = 1).
Before an application attempts to use the POPCNT instruction, it must check that the processor supports SSE4.2 (if CPUID.01H:ECX.SSE4_2[bit 20] = 1) and POPCNT (if CPUID.01H:ECX.POPCNT[bit 23] = 1).
Цитата 12.13.4 Checking for AESNI Support
Before an application attempts to use AESNI instructions or PCLMULQDQ, the application should follow the steps illustrated in Section 11.6.2, “Checking for SSE/SSE2 Support.” Next, use the additional step provided below:
Check that the processor supports AESNI (if CPUID.01H:ECX.AESNI[bit 25] = 1);
Check that the processor supports PCLMULQDQ (if CPUID.01H:ECX.PCLMULQDQ[bit1] = 1)
Одни с годами умнеют, другие становятся старше.
Ваша оценка: Нет
flat assembler (FASM) - компилятор для ассемблера с открытым исходным кодом для процессоров x86 и x86-64 (включая архитектуры AMD64 и Intel 64).
Доступны варианты для DOS, Windows, Linux и Unix.
FASM написан на самом себе, обладает небольшими размерами и очень высокой скоростью компиляции, имеет богатый и ёмкий макро-синтаксис, позволяющий автоматизировать множество рутинных задач. Поддерживаются как объектные форматы, так и форматы исполняемых файлов. Это позволяет в большинстве случаев обойтись без компоновщика. В остальных случаях нужно использовать сторонние компоновщики, поскольку таковой вместе с fasm не распространяется.
Помимо базового набора инструкций процессора и сопроцессора FASM поддерживает наборы инструкций MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AVX и 3DNow. а также EM64T и AMD64 (включая AMD SVM и Intel SMX).
Разместил: vikos 22 Март 2011 в 09:27
Вход в систему Последние комментарии12 недель 4 дня назад
12 недель 4 дня назад
13 недель 20 часов назад
43 недели 2 дня назад
1 год 3 дня назад
Новые обсуждения форумаLinsoft.info (с) Все права защищены. 2010-2015
Поддерживаемые Вашим компьютером наборы инструкций можете узнать, посмотрев спецификацию к утановленному в компьютере центральному порцессору.
Я полагаю, что Вы хотите установить себе на компьютер Apple Mac OS X :)
Наличие в названии образа диска SSE2, SSE3 означает, что в образе есть ядра для этой ОС, поддерживающие и умеющие работать с этими наборами инструкций.
PPF - это пакеты обновлений для Mac OS X. Наличие в имени дистрибутива этих выражений означает, что соответствующие пакеты обновлений встроены в этот дистрибутив.
Цитата: "ppf1 repaired the following: networking issues, removed natit and added titan, added automated permission repair commands.
ppf2 repaired a problem with the disk utility."
Mike Noldman Оракул (72568) 7 лет назад
SSE2 (англ. Streaming SIMD Extensions 2, потоковое SIMD-расширение процессора) — это SIMD (англ. Single Instruction, Multiple Data, Одна инструкция — множество данных) набор инструкций, разработанный Intel, и впервые представленный в процессорах серии Pentium 4.
SSE2 использует восемь 128-битных регистров (xmm0 до xmm7), включённых в архитектуру x86 с вводом расширения SSE, каждый из которых трактуется как 2 последовательных значения с плавающей точкой двойной точности. SSE2 включает в себя набор инструкций, который производит операции со скалярными и упакованными типами данных. Также SSE2 содержит инструкции для потоковой обработки целочисленных данных в тех же 128-битных xmm регистрах, что делает это расширение более предпочтительным для целочисленных вычислений, нежели использование набора инструкций MMX, появившегося гораздо раньше.
Преимущество в производительности достигается в том случае, когда необходимо произвести одну и ту же последовательность действий над большим набором однотипных данных.
Материал из Википедии — свободной энциклопедии
Текущая версия (не проверялась)
Перейти к: навигация, поиск
SSE3 (PNI — Prescott New Instruction) — третья версия SIMD-расширения Intel, потомок SSE, SSE2 и MMX. Впервые представлено 2 февраля 2004 года в ядре Prescott процессора Pentium 4. В 2005 AMD предложила свою реализацию SSE3 для процессоров Athlon 64 (ядра Venice, San Diego и Newark).
Набор SSE3 содержит 13 инструкций: FISTTP (x87), MOVSLDUP (SSE), MOVSHDUP (SSE), MOVDDUP (SSE2), LDDQU (SSE/SSE2), ADDSUBPD (SSE), ADDSUBPD (SSE2), HADDPS (SSE), HSUBPS (SSE), HADDPD (SSE2), HSUBPD (SSE2), MONITOR (нет аналога в SSE3 для AMD), MWAIT (нет аналога в SSE3 для AMD).
А насчёт ppf1, ppf2 - это патчи корректирующие работу ОС.
Дмитрий Inkognito Профи (688) 7 лет назад
SSE2 (англ. Streaming SIMD Extensions 2, потоковое SIMD-расширение процессора) — это SIMD (англ. Single Instruction, Multiple Data, Одна инструкция — множество данных) набор инструкций, разработанный Intel, и впервые представленный в процессорах серии Pentium 4.
SSE3 (PNI — Prescott New Instruction) — третья версия SIMD-расширения Intel, потомок SSE, SSE2 и MMX. Впервые представлено 2 февраля 2004 года в ядре Prescott процессора Pentium 4. В 2005 AMD предложила свою реализацию SSE3 для процессоров Athlon 64 (ядра Venice, San Diego и Newark).
ppf1, ppf2 - это фиксы для установки MacOS на PC. Например без фиксов образ не будет ставиться с ide привода, только с sata и т. д.