


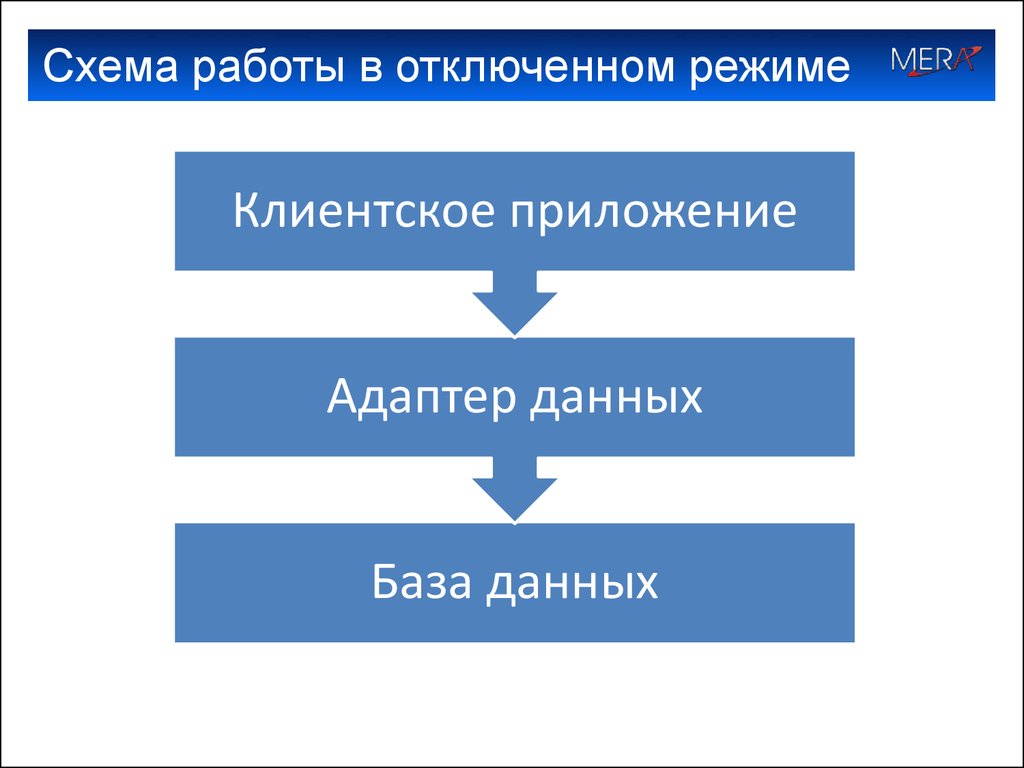




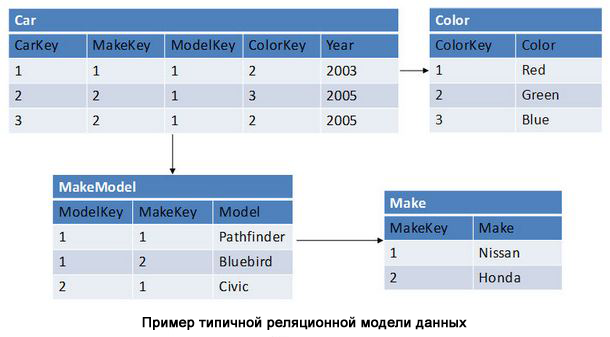
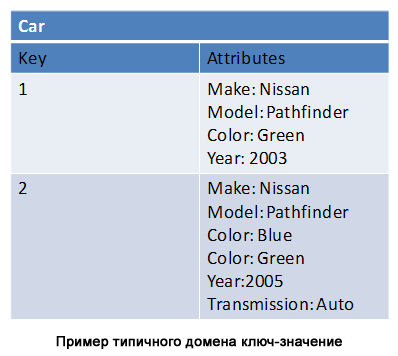
Категория: Руководства
BM Database 2 представляет собой реляционную систему управления базами данных. Она позволяет пользователям работать с реляционными данными, используя язык структурных запросов SQL. Первая реализация этой СУБД появилась в 1983 году для операционной системы MVS [1]. и впоследствии была перенесена на многие другие платформы. Еще более широкую популярность приобрел введенный в DB2 язык SQL, являющийся в настоящий момент общепринятым для работы с реляционными базами данных в архитектуре клиент/сервер.
Изначально разработанная для работы с коммерческими данными, DB2 завоевала сильные позиции на рынке реляционных СУБД как весьма стабильная система, пригодная для автоматизации организаций любого масштаба.
Стремительный прогресс информационных технологий оказывает весьма существенное влияние на решаемые СУБД задачи, и DB2 существенно изменилась за время своего существования.
Современные приложения и их требования к СУБД
Если десять-пятнадцать лет назад наиболее важными приложениями СУБД были экономические и административные базы данных, которые характеризовались достаточно простой моделью данных, то сегодня ситуация изменилась.
В последнее время в связи с быстрым развитием аппаратного обеспечения все большее значение приобретают приложения, работающие с большими объемами данных сложной структуры.
Примерами таких приложений являются САПР, CASE, системы мультимедиа, экспертные системы и т.д. Для них требуется модель данных, которая в наиболее естественной форме выражает как структуру отдельных объектов, так и отношения между ними. При этом модель данных должна отражать не только статические отношения между объектами, но и их поведение и ограничения, которые на них накладываются. Кроме того, модель данных должна быть расширяемой, то есть приложение должно иметь возможность определять свои собственные типы данных вместе с соответствующими операциями, и иметь возможность использовать их для определения новых типов данных, также как и типы данных, предоставляемые системой. Расширяемость является чрезвычайно важной, так как различные приложения часто требуют различных типов данных.
Разумеется, значительная часть таких приложений относится к достаточно специальным областям, и для их реализации используются не базы данных общего применения, а более специализированные средства. Однако новые технологии все более активно внедряются и в традиционных для реляционных СУБД областях. Например, все более очевидна становится тенденция интеграции коммерческих приложений со средствами мультимедиа.
Достоинства реляционного и объектного подхода к построению информационных систем
При разработке базы данных объекты предметной области должны быть описаны в терминах предоставляемой СУБД модели данных. Чем лучше природа данных соответствует предоставляемой модели, тем проще и эффективнее будет схема данных. В случае же несоответствия схема не будет отражать семантики предметной области, что делает ее сложной и неэффективной.
Классическая реляционная модель данных идеально подходила для создания баз данных сравнительно простой структуры и содержащих данные простых типов. Схема типичной экономической или административной базы данных времен разработки DB2 удобно описывается при помощи реляционной модели, так как необходимые данные естественно представляются в виде отношений. При возрастании возможностей аппаратуры реляционные СУБД позволяют увеличить объем хранимых данных и скорость их обработки, но мало применимы для работы с данными новых типов и сложной структуры, так как такие данные сложно моделировать при помощи имеющихся в реляционной модели абстракций.
Для решения таких задач эффективны объектно-ориентированные информационные системы (ООИС), в которых сущности реального мира представляются как объекты данных [2]. Состояние объектов описывается как значения их атрибутов, а их поведение (применимые к ним операции) определяется реализацией их методов. Это позволяет представлять объекты предметной области в естественном для них и семантически значимом виде, что существенно упрощает разработку и модификацию схемы данных. Реляционная модель данных может рассматриваться как подмножество объектно-ориентированной, что накладывает серьезные ограничения на использование реляционных СУБД при построении ООИС. Однако это именно то подмножество, которое на протяжении последних лет используется в большинстве работающих реляционных систем, что привело к детальной разработке этой модели. В результате современные РСУБД отличает совершенство реализаций, обеспечивающее высокую надежность и производительность, в отличие от объектно-ориентированных баз данных, находящихся сегодня на ранней стадии своего развития. Более того, существуют задачи [3]. для которых объектный подход не дает преимуществ.
В такой ситуации подход IBM к созданию ООИС заключается в применении технологий, в наибольшей степени соответствующих специфике решаемой задачи. Так, в системе организации коллективной разработки программного обеспечения Team Connection используется объектно- ориентированная СУБД Object Store, специально лицензированная у компании Object Design. Выбор объектно-ориентированной СУБД определяется при этом необходимостью управлять сравнительно небольшим объемом данных при их сложной структуре и разнообразии методов обработки. Иной подход предлагается IBM для построения корпоративных информационных систем, где приоритетными являются соображения надежности и производительности, а также совместимости с прежними версиями и промышленными стандартами. Полагая, что при современном уровне развития информационных технологий такие характеристики может обеспечить только реляционная СУБД, IBM предлагает для таких систем новую версию DB2, которая сохраняет всю функциональность реляционной СУБД, но расширяет ее новыми средствами, выходящими за рамки реляционной алгебры и призванными снять некоторые ограничения реляционной модели [4,5]. В значительной мере на такой подход влияет и необходимость защиты инвестиций, сделанных пользователями в реляционные технологии, и в известной степени он является компромиссным, однако позволяет снять многие острые проблемы, стоящие перед современными СУБД.
Преодоление ограничений реляционного подхода
Среди наиболее существенных ограничений реляционного подхода можно отметить:Типы данных, определяемые пользователем
Эта версия DB2 дает пользователю возможность определять новые типы данных. Новый тип данных должен соответствовать одному из базовых типов, предоставляемых системой, но для них может быть определена своя семантика. При этом DB2 способна манипулировать такими данными в соответствии с определенной для них логикой. Можно задать набор операций, допустимых для некоторого типа данных, изменив его по сравнению с относящимся к базовому типу.
В DB2 реализован механизм строгой типизации. К данным новоопределенного типа применимы при этом только те операции, которые определены для него самого, а не для базового класса. Для СУБД такой подход предоставляет мощный механизм контроля целостности данных.
Так, можно определить тип "почтовый индекс" как производный от целого, но при этом запретить операции умножения и деления для данных этого типа, как не имеющие смысла, в то время как для базового класса эти операции справедливы.
Два пользовательских типа данных, производные от одного и того же базового, различаются системой, что можно использовать для предотвращения некорректных операций с разнородными данными. Например, определим наряду с упомянутым выше типом "почтовый индекс" другой производный от целого тип "номер телефона". Попытка сравнить "номер телефона" и "почтовый индекс" будет восприниматься системой как ошибка, даже если для каждого из этих типов операция сравнения определена.
DB2/2 и DB2/6000 предоставляют пользователю такие новые типы данных, как большие бинарные объекты (BLOBS) и большие текстовые объекты (CLOBS). BLOBS позволяют хранить данные любого вида размером до двух гигабайт. CLOBS имеют такие же ограничения на размер, но предназначены для хранения текста в виде последовательности однобайтных или двухбайтных символов и могут быть связаны с определенной кодовой страницей.
Наличие таких типов данных позволяет встраивать в реляционные таблицы данные нетрадиционных типов, в первую очередь мультимедиа. Эта возможность приобретает все большее значение для современных приложений, позволяя хранить, например, фотографии сотрудников в базе данных отдела кадров, графические изображения, звук, видео, большие тексты. Основное внимание при этом уделено достижению высокой производительности и надежности, а также снятию ограничений на использование больших объектов. Так, можно создать таблицу, включающую свыше десяти полей, содержащих двухгигабайтные объекты.
Существенным достоинством реализации больших объектов в DB2 является применимость к ним некоторых возможностей SQL. Так, к большим объектам применимы функции для работы со строками, они могут использоваться с оператором конкатенации и с предикатом LIKE. Эти средства можно использовать не только для работы с текстовыми объектами, но и с двоичными. Например функция поиска подстроки может быть полезна как для нахождения заданной фразы в тексте, так и для поиска фильма, содержащего нужный кадр.
Большие возможности при работе с большими объектами предоставляет определение новых типов данных и функций. Это делает возможным задать возможность поиска картины по ее элементу, или операцию сравнения текстов и т.д. Эти преимущества в полной мере используют реляционные расширители DB2, описанные ниже.
Функции, определяемые пользователем
Функции, определяемые пользователем, позволяют скрывать внутреннее представление данных от приложения, обеспечивая некоторую инкапсуляцию данных. Они также позволяют определять новые операции как для базовых типов данных, так и для типов, определяемых пользователем.
Функции, определяемые пользователем, позволяют достичь многократного использования кода за счет того, что операции, общие для различных приложений, хранятся на сервере, а не включаются в каждое отдельное приложение.
Для реализации этих функций используются языки программирования, а для их регистрации в СУБД - введенный в язык определения данных оператор CREATE FUNCTION. Фактически этот оператор связывает пользовательскую функцию с конкретной программой, выполняемой при вызове этой функции. Использование пользовательских функций вместо непосредственного доступа к данным может обеспечить некоторую инкапсуляцию данных, что можно использовать для того, чтобы скрыть от пользователя их внутреннюю структуру.
Кроме того, DB2 поддерживает механизм перегрузки имен пользовательских функций, аналогичный применяемому в ООБД, однако не позволяет связывать функции с конкретными элементами данных, как связаны методы и объекты при объектном подходе.
Дополнительную гибкость функциям, определяемым пользователем, придает способность одновременно работать как с данными DB2, так и другими данными, как, например, файлами, электронной почтой и др.
Возможны два варианта взаимодействия функций, определяемых пользователем, с сервером DB2.
Первый заключается в том, что функция имеет прямой доступ к БД, что позволяет достичь максимальной производительности, но представляет собой потенциальную угрозу работоспособности сервера и целостности данных.
Во втором варианте функция выполняется как отдельный от сервера БД процесс, что обеспечивает защиту данных и СУБД, но снижает производительность.
Пользователь может выбирать оптимальный для своей задачи подход в зависимости от ее специфики.
Триггеры определяют набор операций, которые выполняются при возникновении определенных событий в базе данных, например при обновлении таблицы.
Триггеры могут использоваться для выполнения функций, которые при объектно- ориентированном подходе выполняются методами (например, проверка корректности вводимых значений), или конструктором (присвоение значений при создании новой записи).
Использование триггеров позволяет сделать данные "активными", моделировать не только структуру и свойства, но и поведение хранимых в БД объектов данных.
Хорошим примером применения перечисленных новых возможностей являются реляционные расширители DB2 (DB2 Relational Extenders). Они предоставляют широкие возможности для работы с нетрадиционными данными, используя возможность определения пользовательских типов данных и функций. Для хранения мультимедиа данных расширители используют поддерживаемые DB2 большие объекты, а для поддержания целостности по ссылкам - триггеры.
В настоящее время существует пять реляционных расширителей, позволяющих работать с изображениями, сложными текстовыми документами, видео, аудио, и даже с отпечатками пальцев.
Круг задач, которые можно решать, используя объектные расширения DB2, существенно увеличен по сравнению с классическим реляционным подходом. Заимствовав из объектно-ориентированной модели наиболее необходимые для современных приложений элементы, DB2 сохранила все достоинства реляционной СУБД. Это позволяет использовать при построении корпоративных информационных систем на ее основе как реляционный, так и объектно-ориентированный подход.
В двух последних главах весьма подробно было рассмотрено предложение выборки данных SELECT языка SQL. Обратим теперь наше внимание на предложения обновления данных UPDATE (обновить), DELETE (удалить) и INSERT (вставить). Примечание. Термин «обновить» имеет, к сожалению, в системе DB2 два различных смысла. Он используется как родовой термин для ссылки на все три указанные операции как класс, а с другой стороны, специально для ссылки на операцию UPDATE саму по себе. Для того чтобы различать эти два смысла в данной книге, рассматриваемый термин записывается строчными буквами, когда предполагается его использование в родовом смысле, и прописными, если имеется в виду специфический его смысл.
Как и предложение SELECT, три предложения обновления данных оперируют не только базовыми таблицами, но и представлениями. Однако по причинам, рассмотрение которых выходит за рамки данной главы, не все представления являются обновляемыми. Если пользователь попытается выполнять операцию обновления над необновляемым представлением, система DB2 просто отвергнет эту операцию с соответствующим сообщением для пользователя. Предположим, следовательно, для целей данной главы, что все таблицы, которые будут обновляться, являются базовыми таблицами, а рассмотрение запросов к представлениям и, в частности, обновления представлений отложим до главы 8.
В следующих трех разделах подробно обсуждаются три операции обновления. Синтаксис этих операций следует тому же общему образцу, который был уже показан для операции SELECT. Для удобства в начале соответствующих разделов приводится в общих чертах синтаксис обсуждаемых предложений языка SQL.
6.2. ПРЕДЛОЖЕНИЕ UPDATEПредложение UPDATE имеет следующий общий формат:
SET поле = выражение
Все записи в «таблице», которые удовлетворяют «предикату», обновляются в соответствии с присваиваниями «поле = выражение» во фразе SET (установить).
^
Изменить цвет детали Р2 на желтый, увеличить ее вес на 5 и установить значение города «неизвестен» (NULL).
SET ЦВЕТ = 'Желтый',
WHERE НОМЕР_ДЕТАЛИ = 'Р2';
Для каждой записи, которая должна быть обновлена (т. е. для каждой записи, которая удовлетворяет предикату WHERE, или для всех записей, если фраза WHERE опущена), ссылки во фразе SET на поля этой записи обозначают значения этих полей перед тем, как будет выполнено какое-либо присваивание в этой фразе SET.
^
Удвоить состояние всех поставщиков, находящихся в Лондоне.
SET СОСТОЯНИЕ = 2*СОСТОЯНИЕ
WHERE ГОРОД = 'Лондон';
^
Установить объем поставок равным нулю для всех поставщиков из Лондона.
SET КОЛИЧЕСТВО = О
(SELECT ГОРОД FROM S
WHERE S. НОМЕР_ПОСТАВЩИКА =
6.2.4. ОБНОВЛЕНИЕ НЕСКОЛЬКИХ ТАБЛИЦ
Изменить номер поставщика S2 на S9.
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
SET НОМЕР_ПОСТАВЩИКА = 'S9'
WHERE НОМЕР_ПОСТАВЩИКА = 'S2';
Невозможно обновить более одной таблицы в единственном запросе. Иными словами, в предложении UPDATE должна специфицироваться в точности одна таблица. Поэтому в данном примере мы сталкиваемся со следующей проблемой целостности (точнее, с проблемой целостности по ссылкам): база данных становится противоречивой после выполнения первого предложения UPDATE — она включает теперь некоторые поставки, для которых не имеется соответствующей записи о поставщике, и остается в таком состоянии до тех пор, пока не будет выполнено второе предложение UPDATE. Изменение порядка предложений UPDATE, конечно, не решает эту проблему. Поэтому важно обеспечить выполнение обоих этих предложений, а не только одного. Этот вопрос о поддержании целостности в условиях, когда требуется множество обновлений, детально обсуждается в главе 11. Кроме того, проблема целостности по ссылкам, в частности, подробно описана в Приложении А, а использованный в системе DB2 подход к ее решению представлен в Приложении В.
6.3. ПРЕДЛОЖЕНИЕ DELETEПредложение DELETE имеет следующий общий формат:
Удаляются все записи в «таблице», которые удовлетворяют «предикату».
^
Удалить поставщика S1.
WHERE НОМЕР_ПОСТАВЩИКА = 'S1’.
И снова, если таблица SP в настоящее время содержит какие-либо поставки для поставщика S1, это удаление нарушит непротиворечивость базы данных (сравните с примером 6.2.4; как и в случае предложения UPDATE, нет операций DELETE, воздействующих на несколько таблиц). См. главу 11, а также Приложения А и В.
^
Удалить всех поставщиков из Лондона.
WHERE ГОРОД = 'Лондон';
Удалить все поставки.
SP — все еще известная таблица, но она теперь пуста. Удалить все записи—это не уничтожить таблицу (операция DROP).
^
Удалить все поставки для поставщиков из Лондона.
WHERE S. НОМЕР_ПОСТАВЩИКА =
6.4. ПРЕДЛОЖЕНИЕ INSERTПредложение INSERT имеет следующий общий формат:
INTO таблица [(поле [,поле] .. )]
VALUES (константа [,константа]. );
INTO таблица [(поле [,поле]. )]
В первом формате в «таблицу» вставляется строка, имеющая заданные значения для указанных полей, причем 1-я константа в списке констант соответствует i-му полю в списке полей. Во втором формате вычисляется «подзапрос»; копия результата, представляющего собой, вообще говоря, множество строк, вставляется в «таблицу». При этом 1-й столбец этого результата соответствует f-му полю в списке полей. В обоих случаях отсутствие списка полей эквивалентно спецификации списка всех полей в таблице (см. ниже пример 6.4.2).
^
Добавить в таблицу Р деталь Р7 (город 'Атенс', вес — 2, название и цвет в настоящее время неизвестны).
INTO Р (НОМЕР_ДЕТАЛИ, ГОРОД, BEC)
VALUES ('Р7', 'Атенс', 2);
Создается новая запись для детали с заданным номером, городом и весом, с неопределенными значениями для названия и цвета. Эти два последних поля не должны быть, конечно, определены как NOT NULL в предложении CREATE TABLE для таблицы Р. Порядок слева — направо, в котором поля указаны в предложении INSERT, не обязательно должен совпадать с порядком слева — направо, в котором поля были специфицированы в предложении CREATE (или ALTER).
^
Добавить деталь Р8 в таблицу Р, при этом: название—'Звездочка', цвет — 'Розовый', вес— 14, город — 'Ницца'.
VALUES ('Р8', 'Звездочка', 'Розовый', 14, 'Ницца');
Отсутствие списка полей эквивалентно спецификации списка всех полей в таблице в порядке слева — направо, как они были определены в предложении CREATE (или ALTER). Как и «SELECT * », такая краткая нотация может быть удобной для интерактивного SQL. Она потенциально опасна, однако, во встроенном SQL, т. е. в предложениях SQL, используемых в прикладной программе, в связи с тем, что предполагаемый список полей может изменяться, если для программы заново осуществляется связывание, а определение таблицы было в этом промежутке времени изменено.
^
Вставить новую поставку с номером поставщика S20, номером детали Р20 и количеством 1000.
INTO SP (НОМЕР—ПОСТАВЩИКА, НОМЕР—ДЕТАЛИ, КОЛИЧЕСТВО)
VALUES ('S20', 'Р20', 1000);
Подобно операциям UPDATE и DELETE операция INSERT при отсутствии соответствующего управления также может порождать проблему целостности по ссылкам (см. главу 11, а также Приложения А и В). В рассматриваемом случае система DB2 не проверяет, имеется ли поставщик S20 в таблице S и деталь Р20 в таблице Р.
^
Для каждой поставляемой детали получить ее номер и общий объем поставок, сохранить результат в базе данных (см. пример 5.4.7).
CREATE TABLE ВРЕМЕННАЯ
(НОМЕР_ДЕТАЛИ CHAR (6),
INTO ВРЕМЕННАЯ (НОМЕР_ДЕТАЛИ, ОБЪЕМ_ПОСТАВКИ)
SELECT НОМЕР_ДЕТАЛИ, SUM (КОЛИЧЕСТВО)
GROUP BY НОМЕР_ДЕТАЛИ;
Здесь предложение SELECT выполняется точно так же, как обычно, но результат не возвращается пользователю, а копируется в таблицу ВРЕМЕННАЯ. Теперь с этой копией пользователь может делать все, что он пожелает — делать дальнейшие запросы, печатать и даже обновлять ее. Никакая из этих операций не будет оказывать какого-либо влияния на первоначальные данные. В конечном счете таблицу ВРЕМЕННАЯ можно будет уничтожить, когда она больше не будет нужна:
DROP TABLE ВРЕМЕННАЯ;
Предыдущий пример очень хорошо показывает, почему свойство замкнутости реляционных систем, обсуждаемое во введении к разделу 4.2, является таким важным. Приведенная полная процедура работает именно в связи с тем, что результатом предложения SELECT является другая таблица. Она не работала бы, если бы результат был чем-либо иным, кроме таблицы.
Между прочим, целевая таблица вовсе не обязательно должна быть первоначально пустой для вставки множества записей, хотя в приведенном примере это так. Если таблица не пуста, новые записи просто добавляются к тем, которые уже имеются.
Одно из важных применений INSERT. SELECT — построение так называемого внешнего соединения. Как указывалось в главе 4, обычное (естественное) соединение двух таблиц не включает в результате строк какой-либо из двух таблиц, для которых нет соответствующих строк в другой таблице. Например, обычное соединение таблиц S и Р по городам не включает какой-либо строки для поставщика S5 или для детали РЗ, поскольку в Атенсе не хранится никакая деталь и нет поставщиков, находящихся в Риме (см. пример 4.3.1). Следовательно, в некотором смысле можно считать, что при обычном соединении теряется информация для таких несоответствующих строк. Однако иногда может потребоваться способность сохранять эту информацию. Рассмотрим следующий пример.
^
Для каждого поставщика получить его номер, фамилию, состояние и город вместе с номерами всех поставляемых им деталей, Если данный поставщик не поставляет вообще никаких деталей, то выдать информацию для этого поставщика, оставляя в результате пробелы вместо номера детали.
CREATE TABLE ВНЕШ_СОЕДИНЕНИЕ
(НОМЕР_ПОСТАВЩИКА CHAR (5),
ФАМИЛИЯ CHAR (20),
НОМЕР_ДЕТАЛИ CHAR (6);
SELECT S.*, SP.HOMEP_ДЕТАЛИ
Здесь 'bb' используется для представления строки пробелов. Пояснение. Первые двенадцать строк приведенного результата, как легко видеть, соответствуют первому из двух INSERT. SELECT и представляют собой обычное естественное соединение таблиц S и SP по номерам поставщиков, за исключением того, что не включен столбец КОЛИЧЕСТВО. Последняя строка результата соответствует второму INSERT. SELECT и сохраняет информацию для поставщика S5, который не поставляет никаких деталей. Полный результат представляет собой внешнее соединение таблиц S и SP по номерам поставщиков, в котором опущен столбец КОЛИЧЕСТВО. В противоположность этому обычное соединение называется иногда внутренним соединением.
Заметим, что нужны два отдельных INSERT. SELECT, поскольку подзапрос не может содержать UNION.
6.5. ЗАКЛЮЧЕНИЕМы подошли к концу детального обсуждения четырех предложений манипулирования данными—SELECT, UPDATE, DELETE и INSERT. Сложности этих предложений (и достаточно серьезные!) связаны, по большей части, с предложением SELECT. Как Вы могли убедиться, после того как достигнуто достаточное понимание предложения SELECT, другие предложения становятся довольно понятными. Конечно, на практике предложение SELECT обычно бывает также довольно простым.
Однако, вопреки сказанному выше, с операциями обновления также связаны две проблемы, которые заслуживают, чтобы о них здесь упомянуть.
— Первой и более важной является проблема целостности по ссылкам, которую мы уже несколько раз затрагивали. Как уже указывалось, в Приложениях А и В содержится основательное обсуждение этой проблемы.
— Вторая проблема состоит в том, что более сложным формам трех предложений обновления свойственно следующее небольшое ограничение. Если фраза WHERE в предложении UPDATE или DELETE включает подзапрос, то во фразе FROM этого подзапроса не должна упоминаться целевая таблица этого UPDATE или DELETE. Аналогичным образом в форме предложения INSERT с подзапросом во фразе FROM в подзапросе не должна упоминаться таблица, которая является целевой для этого предложения INSERT. Так, например, если нужно удалить всех поставщиков, состояние которых меньше среднего, то следующий запрос не будет работать.








